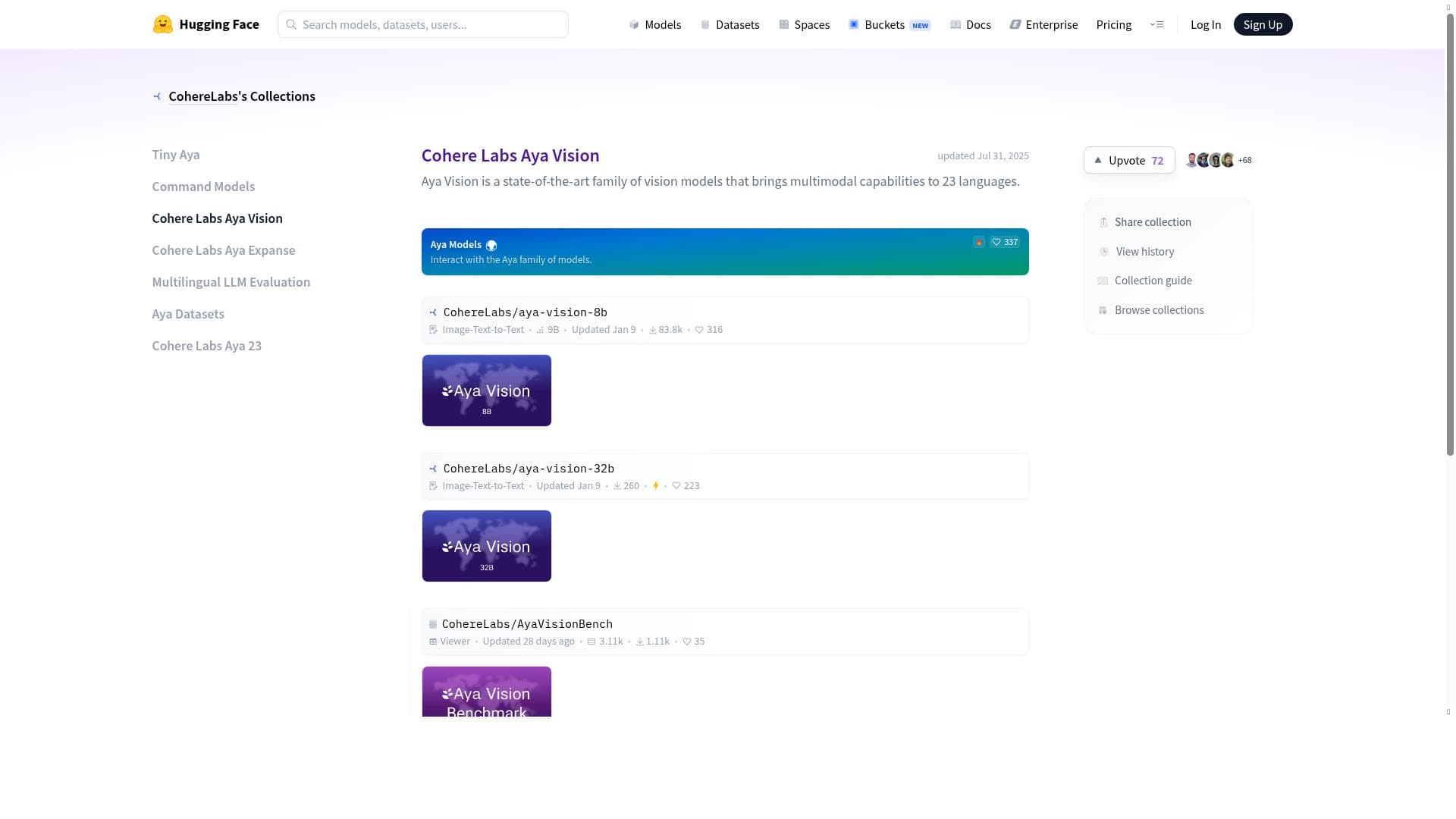
Aya Vision is a powerful open-weights multilingual and multimodal vision AI model from Cohere For AI, designed to outperform larger models on complex multilingual vision tasks. Ideal for developers and researchers needing state-of-the-art vision capabilities across 23 languages, Aya Vision is freely accessible on Hugging Face and Kaggle, enabling broad experimentation and deployment.

Description
Aya Vision, from Cohere For AI, is the open-weights, multilingual, multimodal models (8B & 32B). Outperforms larger models on multilingual vision tasks. Available on Hugging Face and Kaggle.
Detailed Description
Aya Vision, developed by Cohere For AI, is an advanced open-weights AI model suite designed to excel in multilingual and multimodal vision tasks. Available in two model sizes, 8 billion and 32 billion parameters, Aya Vision is engineered to deliver state-of-the-art performance across diverse languages and image-based applications. Its core purpose is to provide researchers, developers, and enterprises with accessible, high-performing vision models that outperform larger counterparts in multilingual contexts, making it a powerful tool for tasks that require understanding and interpreting visual data across multiple languages. At its core, Aya Vision combines sophisticated vision modeling with multimodal capabilities, enabling it to process and analyze not just images but also integrate textual and contextual information. This makes it highly versatile for applications such as image captioning, visual question answering, and cross-lingual image recognition. Supporting 23 languages, Aya Vision stands out in its ability to handle a broad linguistic spectrum, which is critical for global applications where language diversity is a key challenge. The open-weights nature of the models means that users can access, modify, and deploy the models freely, fostering innovation and customization. Aya Vision is particularly well-suited for AI researchers, data scientists, and developers working on multilingual vision projects, including academic research, content moderation, e-commerce, and accessibility tools. For example, companies operating in international markets can leverage Aya Vision to build applications that understand and interpret product images and descriptions in multiple languages, enhancing user experience and operational efficiency. Additionally, Kaggle users and the Hugging Face community benefit from its availability on these platforms, facilitating experimentation, benchmarking, and integration into existing AI workflows. One of the most attractive aspects of Aya Vision is its pricing model—it is offered completely free of charge. This accessibility lowers the barrier to entry for cutting-edge vision AI, enabling startups, educational institutions, and independent developers to harness powerful AI capabilities without financial constraints. The free availability on Hugging Face and Kaggle also means that users can quickly test and deploy the models in cloud environments, accelerating development cycles. Compared to alternative vision models, Aya Vision distinguishes itself by delivering superior performance on multilingual vision tasks despite having fewer parameters than some larger models. Its multimodal design and extensive language support provide a competitive edge in scenarios where understanding both visual and linguistic context is crucial. While many vision models excel in monolingual or unimodal settings, Aya Vision’s balanced approach offers a unique combination of scalability, multilingualism, and multimodality. However, users should consider certain limitations. As an open-weights model, deploying Aya Vision at scale requires sufficient computational resources, particularly for the 32B parameter variant. Additionally, while it supports 23 languages, it may not cover all languages or dialects, which could be a constraint for highly specialized or low-resource language applications. Furthermore, as with any AI model, performance can vary depending on the quality and nature of the input data, so careful preprocessing and fine-tuning may be necessary to achieve optimal results. In summary, Aya Vision is a cutting-edge, freely accessible AI vision model suite that excels in multilingual and multimodal tasks. Its combination of state-of-the-art technology, broad language support, and open availability makes it a valuable resource for a wide range of users aiming to build sophisticated vision applications that operate across languages and modalities.
Tool Features
- State-of-the-art vision models
- Multimodal capabilities
- Supports 23 languages
Description
Aya Vision is a powerful open-weights multilingual and multimodal vision AI model from Cohere For AI, designed to outperform larger models on complex multilingual vision tasks. Ideal for developers and researchers needing state-of-the-art vision capabilities across 23 languages, Aya Vision is freely accessible on Hugging Face and Kaggle, enabling broad experimentation and deployment.
Aya Vision, from Cohere For AI, is the open-weights, multilingual, multimodal models (8B & 32B). Outperforms larger models on multilingual vision tasks. Available on Hugging Face and Kaggle.
Detailed Description
Aya Vision, developed by Cohere For AI, is an advanced open-weights AI model suite designed to excel in multilingual and multimodal vision tasks. Available in two model sizes, 8 billion and 32 billion parameters, Aya Vision is engineered to deliver state-of-the-art performance across diverse languages and image-based applications. Its core purpose is to provide researchers, developers, and enterprises with accessible, high-performing vision models that outperform larger counterparts in multilingual contexts, making it a powerful tool for tasks that require understanding and interpreting visual data across multiple languages. At its core, Aya Vision combines sophisticated vision modeling with multimodal capabilities, enabling it to process and analyze not just images but also integrate textual and contextual information. This makes it highly versatile for applications such as image captioning, visual question answering, and cross-lingual image recognition. Supporting 23 languages, Aya Vision stands out in its ability to handle a broad linguistic spectrum, which is critical for global applications where language diversity is a key challenge. The open-weights nature of the models means that users can access, modify, and deploy the models freely, fostering innovation and customization. Aya Vision is particularly well-suited for AI researchers, data scientists, and developers working on multilingual vision projects, including academic research, content moderation, e-commerce, and accessibility tools. For example, companies operating in international markets can leverage Aya Vision to build applications that understand and interpret product images and descriptions in multiple languages, enhancing user experience and operational efficiency. Additionally, Kaggle users and the Hugging Face community benefit from its availability on these platforms, facilitating experimentation, benchmarking, and integration into existing AI workflows. One of the most attractive aspects of Aya Vision is its pricing model—it is offered completely free of charge. This accessibility lowers the barrier to entry for cutting-edge vision AI, enabling startups, educational institutions, and independent developers to harness powerful AI capabilities without financial constraints. The free availability on Hugging Face and Kaggle also means that users can quickly test and deploy the models in cloud environments, accelerating development cycles. Compared to alternative vision models, Aya Vision distinguishes itself by delivering superior performance on multilingual vision tasks despite having fewer parameters than some larger models. Its multimodal design and extensive language support provide a competitive edge in scenarios where understanding both visual and linguistic context is crucial. While many vision models excel in monolingual or unimodal settings, Aya Vision’s balanced approach offers a unique combination of scalability, multilingualism, and multimodality. However, users should consider certain limitations. As an open-weights model, deploying Aya Vision at scale requires sufficient computational resources, particularly for the 32B parameter variant. Additionally, while it supports 23 languages, it may not cover all languages or dialects, which could be a constraint for highly specialized or low-resource language applications. Furthermore, as with any AI model, performance can vary depending on the quality and nature of the input data, so careful preprocessing and fine-tuning may be necessary to achieve optimal results. In summary, Aya Vision is a cutting-edge, freely accessible AI vision model suite that excels in multilingual and multimodal tasks. Its combination of state-of-the-art technology, broad language support, and open availability makes it a valuable resource for a wide range of users aiming to build sophisticated vision applications that operate across languages and modalities.
Frequently Asked Questions
What is Aya Vision?
Aya Vision is an open-weights AI model suite developed by Cohere For AI that specializes in multilingual and multimodal vision tasks. It offers two model sizes, 8B and 32B parameters, designed to process and understand images alongside textual data across 23 languages.
How much does Aya Vision cost?
Aya Vision is available for free, allowing users to access and utilize the models without any cost.
Who is Aya Vision best for?
Aya Vision is best suited for AI researchers, developers, data scientists, and enterprises working on multilingual vision applications such as image captioning, visual question answering, and cross-lingual image recognition.
What are the main features of Aya Vision?
The main features include state-of-the-art vision modeling, multimodal capabilities that integrate visual and textual data, and support for 23 different languages, enabling robust performance on multilingual vision tasks.
Does Aya Vision offer a free trial?
Aya Vision is fully free to use, so there is no need for a separate free trial.
What integrations does Aya Vision support?
Aya Vision is available on Hugging Face and Kaggle, making it easy to integrate into AI workflows and cloud-based experimentation platforms.
How does Aya Vision work?
Aya Vision works by leveraging large-scale transformer-based models trained on multimodal data, allowing it to analyze and interpret images in conjunction with textual information across multiple languages to perform tasks like image recognition and captioning.
Reviews
No reviews yet. Be the first to share your experience.