Description
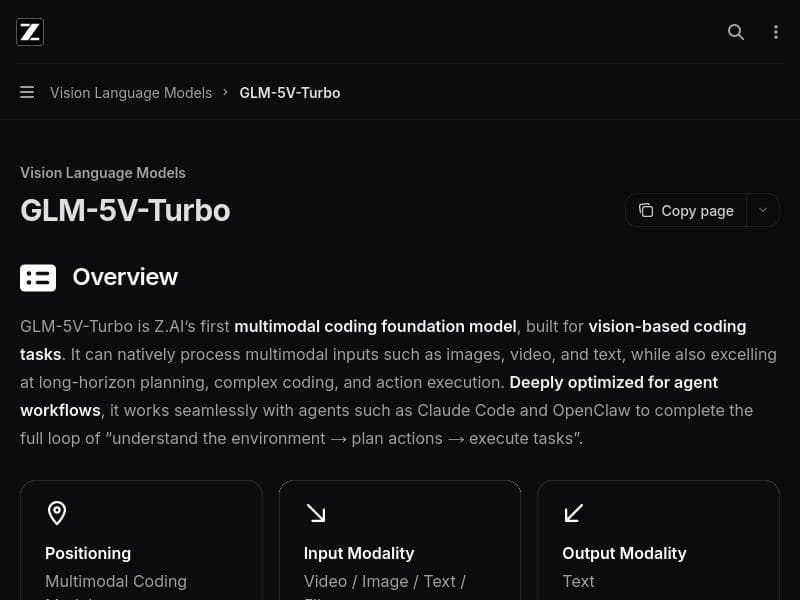
GLM-5V-Turbo is Z.AI's pioneering multimodal coding model that uniquely combines advanced video reasoning with code generation and debugging. Ideal for developers and AI professionals working with complex visual data, it transforms images, videos, and UI layouts into actionable code, streamlining workflows and accelerating development.

GLM-5V-Turbo is Z.AI's first multimodal coding model. It understands images, video, files, and UI layouts, then turns that visual context into runnable code, debugging help, and stronger agent workflows with Claude Code and OpenClaw.
Detailed Description
GLM-5V-Turbo is a cutting-edge multimodal coding model developed by Z.AI, designed to revolutionize how developers and AI practitioners interact with visual and textual data. At its core, GLM-5V-Turbo processes and comprehends a wide array of input types including images, video content, files, and user interface layouts. This broad understanding enables the model to convert complex visual contexts into executable code, provide debugging assistance, and enhance agent workflows through integrations with Claude Code and OpenClaw. The model's primary purpose is to bridge the gap between visual data interpretation and code generation, making it an indispensable tool for projects that require deep video and image analysis combined with programming automation. One of the standout features of GLM-5V-Turbo is its advanced video reasoning capability. Unlike traditional models that focus solely on static images or text, GLM-5V-Turbo excels at interpreting dynamic video content, extracting meaningful insights, and understanding temporal relationships within video frames. This capability is optimized for high-performance video analysis, ensuring rapid and accurate processing even with complex footage. Additionally, the model supports multi-modal input, seamlessly integrating vision and language understanding to provide a holistic analysis of the input data. This integration allows GLM-5V-Turbo to not only recognize visual elements but also contextualize them with accompanying textual information, resulting in more precise and relevant code generation and debugging suggestions. GLM-5V-Turbo is particularly suited for developers, AI researchers, and enterprises working on projects that involve complex video content interpretation, such as automated video editing, surveillance analysis, interactive UI design, and multimedia content generation. Its ability to convert visual context into runnable code makes it ideal for teams looking to automate workflows that traditionally required manual coding based on visual inputs. For instance, software engineers can leverage GLM-5V-Turbo to generate code snippets from UI layouts or video demonstrations, significantly accelerating development cycles. Moreover, its debugging assistance capabilities help reduce errors by providing context-aware suggestions derived from the visual data. In terms of pricing, GLM-5V-Turbo follows a freemium model, allowing users to access basic features at no cost while offering premium capabilities through paid plans. This approach enables individuals and small teams to experiment with the tool and evaluate its effectiveness before committing to a subscription. Detailed pricing tiers and feature breakdowns are available on the official Z.AI documentation site, ensuring transparency and flexibility for different user needs. When compared to alternative multimodal AI models, GLM-5V-Turbo stands out due to its specialized focus on video reasoning combined with code generation. While many models support image and text inputs, few offer the same level of integration between video analysis and runnable code output. Its partnerships with Claude Code and OpenClaw further enhance its utility by embedding it within robust agent workflows, providing a seamless experience for developers. However, users should consider that the model's advanced capabilities may require a learning curve to fully harness its potential, and performance can vary depending on the complexity of the input data. Notable limitations include the potential for reduced accuracy with extremely noisy or low-quality video inputs, as well as the need for sufficient computational resources to handle high-resolution video processing efficiently. Additionally, while the freemium pricing model is accessible, some advanced features and integrations may only be available in paid plans, which could be a consideration for budget-conscious users. Overall, GLM-5V-Turbo represents a significant advancement in multimodal AI coding tools, offering powerful features for those seeking to merge visual understanding with programming automation.
Tool Features
- Advanced video reasoning capabilities
- Multi-modal input support combining vision and language
- Optimized for high performance in video analysis
- Integration of vision and language understanding
- Designed for complex video content interpretation
Description
GLM-5V-Turbo is Z.AI's pioneering multimodal coding model that uniquely combines advanced video reasoning with code generation and debugging. Ideal for developers and AI professionals working with complex visual data, it transforms images, videos, and UI layouts into actionable code, streamlining workflows and accelerating development.
GLM-5V-Turbo is Z.AI's first multimodal coding model. It understands images, video, files, and UI layouts, then turns that visual context into runnable code, debugging help, and stronger agent workflows with Claude Code and OpenClaw.
Detailed Description
GLM-5V-Turbo is a cutting-edge multimodal coding model developed by Z.AI, designed to revolutionize how developers and AI practitioners interact with visual and textual data. At its core, GLM-5V-Turbo processes and comprehends a wide array of input types including images, video content, files, and user interface layouts. This broad understanding enables the model to convert complex visual contexts into executable code, provide debugging assistance, and enhance agent workflows through integrations with Claude Code and OpenClaw. The model's primary purpose is to bridge the gap between visual data interpretation and code generation, making it an indispensable tool for projects that require deep video and image analysis combined with programming automation. One of the standout features of GLM-5V-Turbo is its advanced video reasoning capability. Unlike traditional models that focus solely on static images or text, GLM-5V-Turbo excels at interpreting dynamic video content, extracting meaningful insights, and understanding temporal relationships within video frames. This capability is optimized for high-performance video analysis, ensuring rapid and accurate processing even with complex footage. Additionally, the model supports multi-modal input, seamlessly integrating vision and language understanding to provide a holistic analysis of the input data. This integration allows GLM-5V-Turbo to not only recognize visual elements but also contextualize them with accompanying textual information, resulting in more precise and relevant code generation and debugging suggestions. GLM-5V-Turbo is particularly suited for developers, AI researchers, and enterprises working on projects that involve complex video content interpretation, such as automated video editing, surveillance analysis, interactive UI design, and multimedia content generation. Its ability to convert visual context into runnable code makes it ideal for teams looking to automate workflows that traditionally required manual coding based on visual inputs. For instance, software engineers can leverage GLM-5V-Turbo to generate code snippets from UI layouts or video demonstrations, significantly accelerating development cycles. Moreover, its debugging assistance capabilities help reduce errors by providing context-aware suggestions derived from the visual data. In terms of pricing, GLM-5V-Turbo follows a freemium model, allowing users to access basic features at no cost while offering premium capabilities through paid plans. This approach enables individuals and small teams to experiment with the tool and evaluate its effectiveness before committing to a subscription. Detailed pricing tiers and feature breakdowns are available on the official Z.AI documentation site, ensuring transparency and flexibility for different user needs. When compared to alternative multimodal AI models, GLM-5V-Turbo stands out due to its specialized focus on video reasoning combined with code generation. While many models support image and text inputs, few offer the same level of integration between video analysis and runnable code output. Its partnerships with Claude Code and OpenClaw further enhance its utility by embedding it within robust agent workflows, providing a seamless experience for developers. However, users should consider that the model's advanced capabilities may require a learning curve to fully harness its potential, and performance can vary depending on the complexity of the input data. Notable limitations include the potential for reduced accuracy with extremely noisy or low-quality video inputs, as well as the need for sufficient computational resources to handle high-resolution video processing efficiently. Additionally, while the freemium pricing model is accessible, some advanced features and integrations may only be available in paid plans, which could be a consideration for budget-conscious users. Overall, GLM-5V-Turbo represents a significant advancement in multimodal AI coding tools, offering powerful features for those seeking to merge visual understanding with programming automation.
Frequently Asked Questions
What is GLM-5V-Turbo?
GLM-5V-Turbo is Z.AI's first multimodal coding model that understands images, videos, files, and UI layouts to generate runnable code, provide debugging assistance, and enhance agent workflows through integrations with Claude Code and OpenClaw.
How much does GLM-5V-Turbo cost?
GLM-5V-Turbo offers a freemium pricing model, allowing users to access basic features for free with additional premium capabilities available through paid plans. Detailed pricing information can be found on the official Z.AI documentation website.
Who is GLM-5V-Turbo best for?
It is best suited for developers, AI researchers, and enterprises working on projects involving complex video content interpretation, automated code generation from visual data, and enhanced debugging workflows.
What are the main features of GLM-5V-Turbo?
Key features include advanced video reasoning capabilities, multi-modal input support combining vision and language, high-performance video analysis optimization, integration of vision and language understanding, and design tailored for complex video content interpretation.
Does GLM-5V-Turbo offer a free trial?
Yes, GLM-5V-Turbo follows a freemium model, providing free access to basic features which effectively serves as a free trial for users to evaluate the tool before opting for paid plans.
What integrations does GLM-5V-Turbo support?
GLM-5V-Turbo integrates with Claude Code and OpenClaw to enhance agent workflows, enabling seamless transitions from visual data understanding to code generation and debugging assistance.
How does GLM-5V-Turbo work?
GLM-5V-Turbo processes multimodal inputs such as images, videos, files, and UI layouts by combining vision and language understanding. It interprets the visual context to generate runnable code, assist with debugging, and improve agent workflows through its advanced video reasoning and integration capabilities.
Socials
Use ToolReviews
No reviews yet. Be the first to share your experience.