Latest AI News
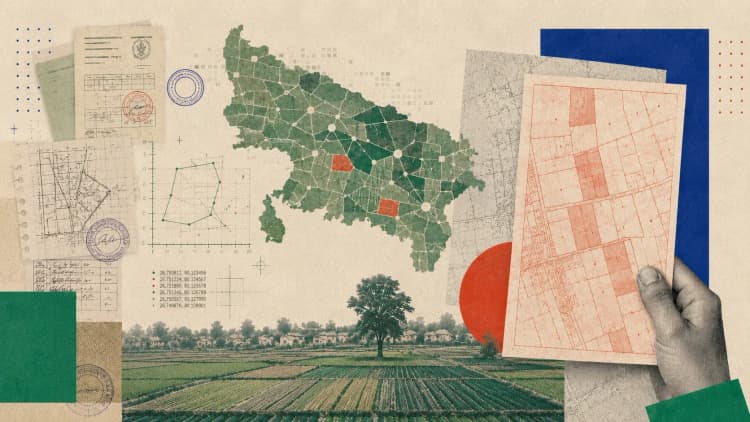
How an Engineer Used Claude to Reclaim Ancestral Property in Uttar Pradesh
A decade after his father passed away, Zahid Khan still couldn’t point to his family’s ancestral land on a map. He then turned to AI.
View
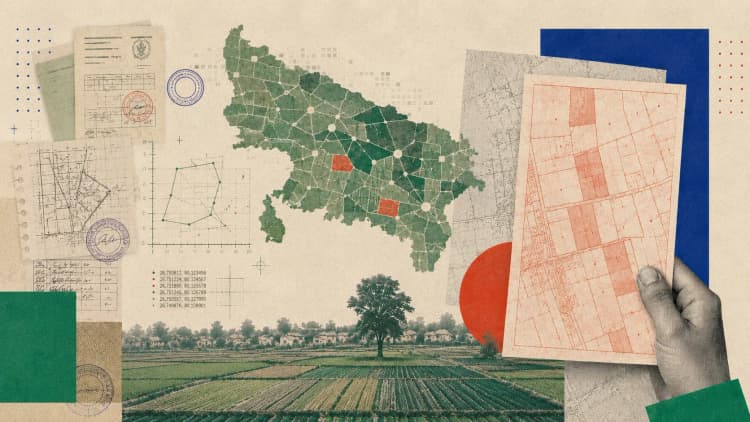
He Inherited Land in Uttar Pradesh. Claude Helped Him Find It.
A decade after his father passed away, Zahid Khan still couldn’t point to his family’s ancestral land on a map. He then turned to AI.
View

The ‘together tech’ wave might be the most intriguing startup bet of 2026
While the AI fundraising machinekeeps breaking its own records, some founders are building in the other direction. Mirror founder Brynn Putnam just raised money forBoard, a startup focused on bringing people together through in-person games and social experiences.Cyberdeck creators are going viralcrafting whimsical DIY computers that literally encourage users to touch grass. Unlike theAI-free browser crowd, this doesn’t just feel like backlash, but also people genuinely gravitating toward things that feel a little more human. On this episode of TechCrunch’sEquitypodcast, Kirsten Korosec, Anthony Ha, and Sean O’Kane dig into the week’s headlines, from the “together tech” wave to what Anthropic’s confidential IPO filing means against the backdrop of Alphabet’s $80 billion AI raise, and whether the money is all flowing back to the big guys anyway. Listen to the full episode to hear: Subscribe to Equity onYouTube,Apple Podcasts,Overcast,Spotifyand all the casts. You also can follow Equity onXandThreads, at @EquityPod.
View

Google will pay SpaceX $920M per month for compute
SpaceX has lined up another compute deal ahead of its historic IPO, this time with Google. The company announced the dealin a regulatory filing on Friday. Under the terms of the deal, Google will pay SpaceX $920 million per month from October 2026 through June 2029 for access to “approximately 110,000 NVIDIA GPUs, CPUs, memory, and other related components.” The deal is similar in length and scope to the one SpaceXannouncedwith Anthropic in late May. As part of that deal, Anthropic agreed to pay SpaceX $1.25 billion per month through 2029 to rent all the available compute from its Colossus 1 data center near Memphis, Tennessee, that xAI — now part of SpaceX — originally built for its own artificial intelligence efforts. Google’s deal appears to be paying for roughly half the amount of compute that Anthropic has access to at Colossus 1. SpaceX didn’t say which specific data center Google would be using. CEO Elon Musk has previously suggested his company would reserve the Colossus 2 data center for xAI. Anthropic was significantly limited in its compute capacity prior to its deal with SpaceX, raising usage limits on the same day the deal was announced. Google is in a very different position, with some estimates naming it as the world’slargest single owner of AI compute. In a statement, a Google representative described the deal as a result of unexpected demand for itsrecently launched AI products. “Google Cloud and SpaceX are long-time partners,” Google said in a statement. “This is a short-term, timely agreement to ensure we have bridge capacity to meet surging customer demand for our agent platform, Gemini Enterprise, which has been even higher than we expected.” But its parent company Alphabet is on a spending spree. Alphabet has alreadycommittedto more than $180 billion in capital expenditures this year and has said it expects that to “significantly increase” in 2027. To help with that, Alphabet recently announced an $80 billion equity sale. Also like the Anthropic deal, the agreement with Google includes a cancellation clause. Both SpaceX and Google have the option to terminate the agreement with 90 days’ notice after December 31, 2026. Google’s access to the data center will ramp up “through September at a reduced fee,” according to the filing. “If we fail to deliver access to the committed amount of GPUs by September 30, 2026, then following a one-month grace period, Google may immediately terminate the agreement or accept the number of GPUs provided” with a reduction in the monthly fees, it reads. SpaceX announced the deal just one week before the company’s stock is expected to start trading on the Nasdaq exchange. Paperwork filed with the Securities and Exchange Commission shows the company is aiming to raise around $75 billion at a valuation of around $1.75 trillion — making it the largest in history. Google is a longtime investor in SpaceX. Its stake in Musk’s company is expected to be worth more than $100 billionafter the IPO. The companies are alsoreportedlyin talks to try to build orbital data centers — a major component of SpaceX’s future plans post-IPO.
View

Startup Battlefield 200 applications officially close in 3 days
Founders, your window to enterStartup Battlefield 200closes in just three short days. Applications for Startup Battlefield 200 officially close on June 8, 11:59 p.m. PT. Do not wait any longer. Secure your shot at competing on the Disrupt Stage atTechCrunch Disrupt 2026this October at San Francisco’s Moscone West. Thousands of startups have already stepped forward. If you’re building a company with the potential to reshape an industry, now is the time to make your move. Apply or nominate a startup before the deadline. Startup Battlefield 200is where ambitious early-stage startups go from unknown to impossible to ignore. Selected founders will take the spotlight atDisrupt, pitching live in front of top investors, influential media, and the global startup ecosystem. One startup will take home $100,000 in equity-free funding, but every selected company gains exposure that can accelerate growth, attract customers, and open doors to future fundraising opportunities. Over the years, Startup Battlefield alumni have collectively raised more than $32 billion and achieved more than 250 exits. Alumni have gone on to be acquired by companies such as Microsoft, Google, Salesforce, Uber, and Amazon. The competition has also helped launch companies such as Dropbox, Discord, Mint, Fitbit, and Trello. In a competitive fundraising market, standing out has never been more important.Startup Battlefield 200offers founders a rare opportunity to put their companies directly in front of investors, media, customers, and potential partners. Selected startups receive: TechCrunch is looking for bold early-stage startups with a working MVP and a vision capable of disrupting an industry. Bootstrapped, pre-seed, and seed-stage startups are encouraged to apply. Select Series A startups in capital-intensive sectors may also qualify. If you’re building a category-defining company,this is your opportunity to prove it on one of the biggest stages in tech. The application window closes June 8, and every application is reviewed by the TechCrunch team. With only three days remaining, this is your chance to put your startup in front of investors, media, customers, and future partners all in one place. Apply or nominate a startupbefore the deadline, and earn your place among the next generation of Startup Battlefield competitors.
View

The token bill comes due: Inside the industry scramble to manage AI’s runaway costs
Across the industry, companies are starting to balk at the price of AI.Uber blew throughits entire 2026 AI coding budget by April.Microsoft revokedits developers’ Claude Code licenses months after enabling them. A Priceline employee told TechCrunch that a routine Cursor contract renewal came back 4-5x more expensive. Even though per-token prices have fallen, the push for more AI adoption and increasingly autonomous agents have driven token consumption higher and higher. Companies that gorged themselves in early 2025 on all-you-can-eat subscriptions are now scrambling to understand where their money is going, pull back spending, and figure out whether they can salvage some ROI from the wreckage of their budgets. Meanwhile, a market is forming to meet them there. Startups, established vendors, and a new standards body are all racing to give companies the tools and language to track what they spend. “Six months ago, I would have a conversation with a customer and it would be all about ‘What can it do? Is it good enough?’” Alexander Embiricos, OpenAI’s head of enterprise, told TechCrunch at an event in New York City this week. “Our conversations are never about that now. Now the conversations are about, ‘hey, we’re spending so much. What visibility do you have? What auditability do you have? What token controls do you have? What is the efficiency of your models?’” It’s against this backdrop that the Linux Foundation this week unveiled plans for the Tokenomics Foundation, a new standards body that aims to instill the same cost discipline around AI tokens that FinOps did for cloud spend. “In April and May, I started hearing from companies: ‘Oh my god, we are 3x over our entire 2026 token budget and it’s only April,’” J.R. Storment, executive director of the FinOps Foundation, a project under the Linux Foundation, told TechCrunch. “We started hearing existential crises, and the whole conversation shifted fromtokenmaxxingand ‘go fast’ to ‘we need guardrails, how do we control this?’” The cries heard round the tech world followed fervent demands from CEOs pushing their teams to use the best models and move fast, costs be damned. New models released in November like Anthropic’s Claude Opus 4.5, OpenAI’s GPT-5.1, and Google’s Gemini 3 Pro brought significant improvements to agentic tools, which have multiplied consumption. It’s how one companyreportedlyfound itself with a $500 million Claude bill after forgetting to set usage limits for employees. “It’s like the crack-cocaine epidemic,” said Chris Reed, senior director of IT finance at Priceline, noting the company had begun placing token limits on certain groups. “They let you try it to get you hooked on it, and now you’re kind of beholden to it.” Vitaly Gordon, CEO of engineering operations platform Faros AI, said he recently spoke to a CTO who told him: “One of my engineers spent $40,000 on tokens last month, and I genuinely don’t know whether I should stop him or should I go and tell everyone else to be like him.“ A Marchsurveyby Faros found that among 20,000 developers, output was rising, but so were bugs and rewrites. Jellyfish, an engineering management platform, similarly found engineers who used the most tokens were about twice as productive as those who used AI less, but they spent 10x the number of tokens to get there. Nicholas Arcolano, head of research at Jellyfish, told TechCrunch via email that expenditure on AI is exploding in large part due to agentic features, with per-developer consumption rising about 18.6x in nine months. All in all, these stats make the productivity case murkier than the spending suggests. “Whether extreme spend pays off comes down to the ultimate business value of shipped code (e.g. revenue), which most companies still can’t measure,” Arcolano said. At least some of that measurement issue is the sheer scale at which AI is being used today. “Tracking cloud costs is a hundreds-of-millions-of-rows-a-month data problem,” Storment said. “Tracking token costs is a trillions-of-rows-a-month data problem. You can’t just stick that into whatever spreadsheet or even basic tool. You’ve got to fundamentally rethink your tooling, your specs and your accounting systems to do that.” At Priceline, Reed is already seeing discrepancies. He noted issues between a vendor’s reported usage and Priceline’s internal data. “I started my career in telecom expense management, and I’m seeing all the same parallels, from telecom to cloud to AI,” he said. “Anytime you introduce something new, it’s ripe for billing errors and audit and optimization opportunities.” A market is beginning to form around this problem. There are the pure-play companies, like Pay-i, which tracks, measures, and optimizes the costs and performance of GenAI investments.Paid, meanwhile, lets developers track costs, measure usage, and bill users based on actual value rather than subscription fees. Then there are companies like Jellyfish, Waydev, and Faros AI, which all provide AI agent monitoring to prove the ROI of developer tools. Storment says most of the 180 vendors within the FinOps Foundation are leaning toward this space. Companies with existing distribution are also adding new features to capitalize on this new market. Ramp has recently moved intoAI spend management;DatadogandNew Relichave tacked on services like cloud cost management, token-level observability, and GPU monitoring. At the FinOps X conference next week, AWS is expected to introduce new financial management features geared toward enterprise AI spending. Tiffany Luck, a partner at NEA, thinks token efficiency and observability will likely be added in at the “harness or app layer.” She pointed to Factory, astartupthat makes AI agents for enterprises, which this weeklauncheda model router that automatically picks the right model for every task. Gordon expects frontier labs and other model providers to adopt OpenRouter-style optimization to drive queries to the cheapest models — a trend already showing up on enterprise Claude bills. “The financial report for how much you spend on Anthropic, even if you call the Opus model, some of the spend will be on Sonnet or Haiku, because they are smart enough to do it,” Gordon said. “I think this will become more and more of a thing.” But all these tools are being built without a common language or shared definitions for how much a token costs, what it produces, and how to compare spend across vendors. That’s where the Tokenomics Foundation hopes to prove useful. The Foundation is building a canonical definition and framework for “tokenomics;” open standards, specifications and metrics for AI token usage and billing; as well as new metrics for AI economics, like cost-per-intelligence or tokens-per-watt. It also plans to define metrics across token factory effectiveness and consumption efficiency. The group is planning a formal launch in July, and is about to announce more members at the FinOps X conference next week. “Token economics is fundamentally more abstract and opaque than anything we’ve managed at this scale before,” Nishant Gupta, chief availability officer at Salesforce, said in a statement. “It requires a different operational muscle than the one the industry built for cloud.” That said, Goldman Sachsprojectsglobal token usage to multiply by 24 times by 2030. The companies already over budget need solutions now, and the foundation’s first deliverable is still months away. “Maybe we created a steam engine, but we still haven’t figured out the assembly line,” said Gordon. According to Arcolano, the smart move is broad, moderate adoption. “The best ROI comes from moving the broad middle from low to moderate usage, not pushing heavy users higher,” he said. Russell Brandom and Tim Fernholz contributed to this reporting.
View

The most interesting startups right now want to get you off your phone
Loading the player… While the AI fundraising machinekeeps breaking its own records, some founders are building in the other direction. Mirror founder Brynn Putnam just raised money forBoard, a startup focused on bringing people together through in-person games and social experiences.Cyberdeck creators are going viralcrafting whimsical DIY computers that literally encourage users to touch grass. Unlike theAI-free browser crowd, this doesn’t just feel like backlash, but also people genuinely gravitating toward things that feel a little more human. WatchEquitypodcast hosts Kirsten Korosec, Anthony Ha, and Sean O’Kane dig into the week’s headlines, from the “together tech” wave to what Anthropic’s confidential IPO filing means against the backdrop of Alphabet’s $80 billion AI raise, and whether the money is all flowing back to the big guys anyway. Subscribe to Equity onYouTube,Apple Podcasts,Overcast,Spotifyand all the casts. You also can follow Equity onXandThreads, at @EquityPod.
View

OpenAI Introduces Smarter ChatGPT Memory, Adds Dreaming Architecture
OpenAI has announced a major upgrade to ChatGPT's memory capabilities, allowing the chatbot to make better use of information from previous conversations. The update aims to improve how ChatGPT remembers user preferences, ongoing projects, and personal details over time. OpenAI said the changes are intended to address issues such as outdated memories while making the feature more effective for a growing user base. The new system is built on a redesigned architecture that the company says can manage memory more efficiently at scale.
View

AirTrunk commits $30B to build 5GW of AI data centers in India
Blackstone-backed data center operator AirTrunk said on Thursday it would invest $30 billion in India by 2030, adding to a wave of commitments from technology and infrastructure groups seeking to expand computing capacity in the country. The Australian companysaidit would develop 5 gigawatts of new data center capacity in India, one of the largest commitments to the South Asian nation’s digital infrastructure sector. AirTrunk entered India earlier this year through the acquisition of Lumina CloudInfra. AirTrunk’s commitment underlines India’s growing appeal as a destination for AI infrastructure, as tech companies and investors seek new geographies to expand computing capacity. Data center capacity in the country isprojected to riseto as much as 8GW by 2030 from about 1.5GW today, according to research firm Bernstein. The Indian government has also taken steps to attract investment in AI infrastructure. Earlier this year, New Delhi offered foreign cloud providerstax exemptions through 2047on services sold overseas if those workloads are run from Indian data centers. AirTrunk has already begun laying the groundwork for its expansion in the country. Earlier this week, Maharashtra Chief Minister Devendra Fadnavissaid in a post on Xthat the western Indian state had exchanged a letter of intent for land allotment at the Raigad Pen Growth Center, where AirTrunk is planning a 3GW data center involving an investment of about ₹2 trillion (around $21 billion). The company already has a development pipeline of about 600MW across Mumbai, Chennai and Hyderabad. AirTrunk did not respond to questions on whether the proposed Raigad project would account for most of the planned 5GW capacity, or whether it plans to make additional developments elsewhere in India. The announcement follows a meeting between AirTrunk CEO Robin Khuda and Prime Minister Narendra Modi, whosaid in a post on Xthat the planned investment would help strengthen India’s position as a global hub for cloud computing and artificial intelligence. AirTrunk joins a growing list of companies investing in infrastructure in the country.Amazon,Google,Microsoft,OpenAI, andUberhave announced major investments in cloud and AI infrastructure, while Indian companiesReliance Industries,Adani Group, andTCShave laid out ambitious plans to expand data center capacity. However, data centers require vast amounts of electricity, water and land, and industry executives and analysts have pointed to resource issues as a potential bottleneck, particularly regarding power. Deloitteestimatesdata center build-outs in the Asia Pacific could require tens of terawatt-hours of additional electricity by the end of the decade. AirTrunk’s investment thesis is underpinned by government support, a large pool of technical talent, and access to renewable energy, Khuda said.
View

How Enterprises Can Stop AI From Bleeding Their Tech Budgets
As AI deployment grows, companies must improve governance, monitor ROI, and prioritise business outcomes over usage costs.
View
Sam Altman, Palmer Luckey and Silicon Valley’s Biggest Names Play Mafia
In its latest content experiment, Founders Fund swaps podcasts for Mafia, pitting Silicon Valley’s biggest names against one another.
View
Tamil Nadu Bets ₹18,600 Cr with L&T on Data Centre-Led Industrial Expansion
Three projects are expected to create about 8,200 employment opportunities across the state.
View
